I propose to consider the question, 'Can machines think?'
This should begin with definitions of the meaning of the terms 'machine' and 'think'.
The definitions might be framed so as to reflect so far as possible the normal use of words,
but this attitude is dangerous.
If the meaning of the words 'machine' and 'think' are to be found
by examining how they are commonly used
it is difficult to escape the conclusion that the meaning
and the answer to the question, 'Can machines think?'
is to be sought in a statistical survey such as a Gallup poll. But this is absurd.
- A. M. Turing's (1950, p. 433) 'Computing Machinery and Intelligence'
Acting Rationally
The acting rationally approach is concerned with the underlying principles of rational behaviour
The acting rationally approach is supported by:
The Reinforcement Learning-Based Model of Interaction between an Agent and its Environment
The Rationality Assumption or Expected Utility Hypothesis
The Markov Decision Process
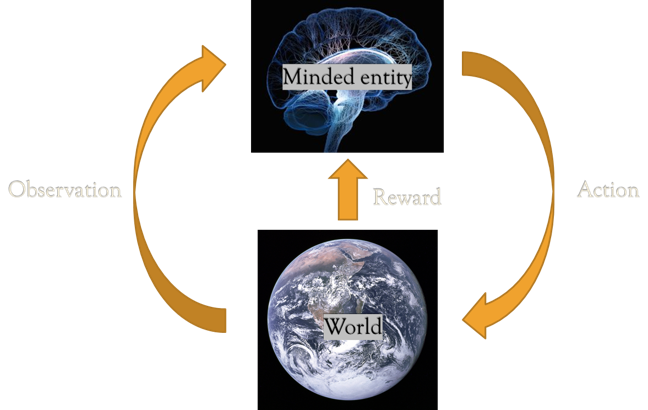
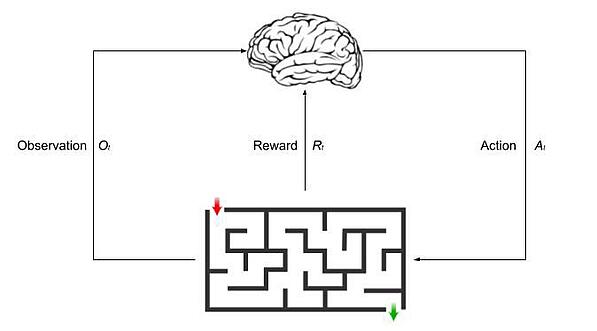
Reinforcement learning-based model
According to the Reinforcement Learning-Based Model of Interaction between an Agent and its Environment:
An agent is a minded entity that perceives through sensors (e.g. eyes, ears, cameras, etc), acts through effectors (e.g. hands, legs, motors, etc)
An agent also interacts with its environment and learns accordingly
At step t, the agent performs action At and receives observation Ot and the scalar reward Rt
The environment receives action At and emits observation Ot + 1 and the scalar reward Rt + 1
A rational action is defined as any action that maximizes the expected value of an objective performance measure, given the percept sequence to date — see also the Rationality Assumption or Expected Utility Hypothesis
Individual decision-making under risk
Decision theory allows for certain computations to be made on the basis of probability-values and utility-values
In addition, the assignment of probability-values and utility-values is constrained by two distinct sets of axioms: the Kolmogorov axioms and the von Neumann-Morgenstern axioms
According to the Rationality Assumption or Expected Utility Hypothesis:
If the von Neumann-Morgenstern axioms are satisfied, then the agent is said to be rational and her preferences can be represented by a utility function
Given n alternative courses of action φ1, φ2, …, φn:
Each action φi has a set of associated outcomes (or action-state pairs), where i ∈ ℕ and i ∈ [1, n]
The utility function allows the agent to assign utility-values consistently to each outcome
Choosing the most appropriate course of action φi according to the preference relation ≽ amounts to choosing the course of action with the maximum expected utility
Andrey Markov
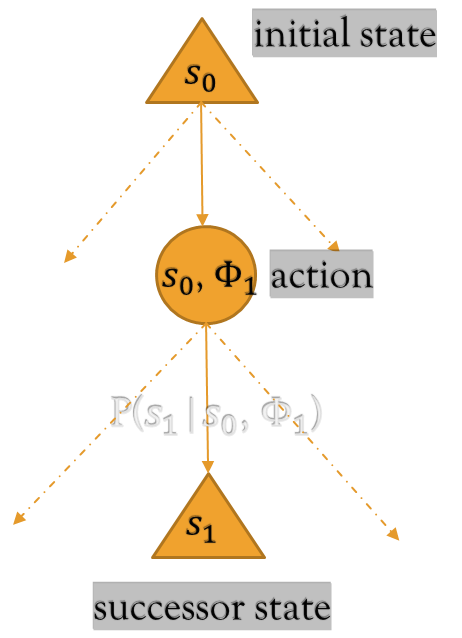
A Markov Decision Process or MDP is a tuple of the form (S, Φ, P, γ, r), where:
S denotes the set of states (including the initial state s0)
Φ denotes the set of actions available to an agent (viz. φ1, φ2, …)
P denotes the transition probability matrix
γ denotes the discount factor
r denotes the reward function
Reinforcement learning, an instantiation of the acting rationally approach, can be modelled as an MDP
There is a non-zero probability P(s1|s0, φ1) that the agent will transition from s0 to a successor state s1 in accordance with the transition probability matrix P
⋮
γ denotes the discount factor, where γ ∈ [0, 1)
γ allows for more immediate rewards to count more than later or time-discounted rewards
Expected total payoff value or cumulative reward = E(r(s0,φ1) + γr(s1,φ2) + γ2r(s2,φ3) + …)
In reinforcement learning, the reward function r is typically specified upfront
Conversely, in inverse reinforcement learning, the reward function is not specified upfront. Rather, it must be extracted from observed optimal behaviour
Given a specified reward function r, the reinforcement learning-based agent attempts to infer an optimal policy π
Given optimal observed behaviour, the inverse reinforcement learning-based agent attempts to infer the reward function r
There is growing interest in the acting rationally approach to AI (Russell & Norvig, 1995, 2002, 2010)


{kind=link}